Esercizi di classificazione con Alberi, Random Forest e Support Vector Machine
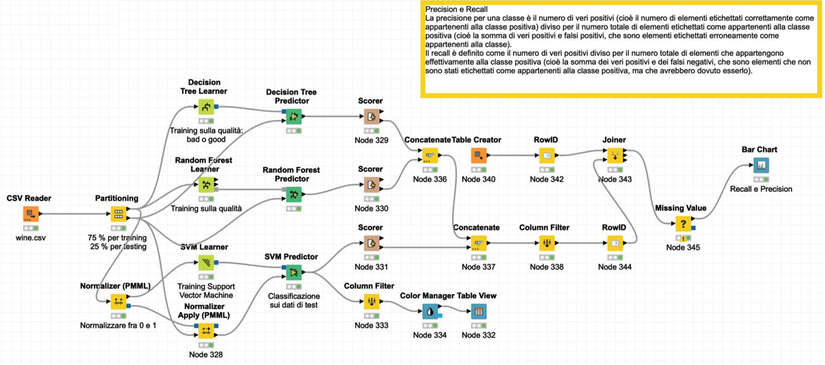
Carissimi Amici, questa volta ho preparato per voi un flusso KNIME che potrete tranquillamente riutilizzare per vostri scopi. Parliamo di classificazione, quindi della scelta di una classe, la prossima volta affronteremo la regressione.
Provate a cambiare i parametri dei nodi e ad usare un vostro database, se avete dei dubbi cercate sul sito di KNIME. Alla prossima!

Ing. Alberto Montanari, Consigliere e Coordinatore Commissione Innovazione, ex Industria 4.0
Albero Decisionale (CART)
Gli alberi
decisionali sono un metodo di apprendimento supervisionato utilizzato sia per
problemi di classificazione che di regressione. L’acronimo CART sta per
“Classification and Regression Trees”. La metodologia CART è stata
sviluppata nel 1984 e si basa sulla creazione di un modello che predice il
valore di una variabile target suddividendo i dati di input in base a feature
(caratteristiche) ad ogni nodo decisionale. I compiti più comuni che
coinvolgono gli alberi decisionali includono il credit scoring e la
segmentazione dei clienti.
1. Costruzione dell’Albero:
L’albero decisionale viene costruito a partire dalla radice e si sviluppa verso il basso, suddividendo il dataset in sottogruppi omogenei. Ad ogni nodo, l’algoritmo seleziona la feature che più efficacemente divide i dati in base alla variabile target. Questa selezione si basa su criteri come la riduzione dell’impurità, misurata tramite indici come Gini o l’entropia per la classificazione, e la somma dei quadrati degli errori per la regressione.
2. Vantaggi:
- Semplicità e interpretabilità: Gli alberi decisionali sono facili da comprendere e interpretare, anche per chi non ha una formazione tecnica approfondita.
- Versatilità: Possono essere utilizzati sia per la classificazione che per la regressione.
- Ridotta necessità di preelaborazione dei dati: Non richiedono una normalizzazione o una scalatura delle feature.
3. Svantaggi:
- Overfitting: Gli alberi decisionali tendono a essere molto complessi e ad adattarsi troppo ai dati di training (overfitting), perdendo capacità di generalizzazione su dati non visti.
- Sensibilità ai cambiamenti nei dati: Piccole variazioni nei dati possono portare alla costruzione di alberi completamente diversi.
4. Pruning:
Per combattere l’overfitting, viene spesso utilizzata una tecnica chiamata “pruning” (potatura), che rimuove i rami non significativi dell’albero, basandosi su criteri di validazione incrociata o altre metriche di errore.
Random Forest
Il Random Forest è un potente algoritmo di apprendimento supervisionato ed è essenzialmente un insieme di alberi decisionali, dove ciascun albero contribuisce alla decisione finale, migliorando la robustezza e la precisione del modello. La previsione del modello è formata da una media dei risultati di ogni singolo albero.
1. Costruzione della Foresta:
- Bagging (Bootstrap Aggregating): Il Random Forest utilizza una tecnica chiamata bagging, che consiste nel creare numerosi sottoinsiemi casuali del dataset originale (con ripetizione) e nell’addestrare un albero decisionale su ciascun sottoinsieme.
- Selezione casuale delle feature: Durante la costruzione di ciascun albero, un sottoinsieme casuale delle feature viene considerato per la divisione in ogni nodo, introducendo ulteriore casualità e riducendo la correlazione tra gli alberi.
2. Vantaggi:
- Riduzione dell’overfitting: Grazie all’aggregazione di molteplici alberi decisionali, il Random Forest riduce il rischio di overfitting rispetto a un singolo albero decisionale.
- Robustezza: È meno sensibile alle variazioni nei dati e più stabile.
- Accuratezza: Spesso fornisce predizioni più accurate rispetto a modelli singoli.
3. Svantaggi:
- Complessità e tempo di calcolo: La costruzione di molti alberi decisionali richiede più tempo di calcolo e risorse rispetto a un singolo albero.
- Meno interpretabilità: A differenza di un singolo albero decisionale, un Random Forest è meno intuitivo e più difficile da interpretare.
4. Valutazione dell’Importanza delle Feature:
Una delle funzionalità utili del Random Forest è la capacità di valutare l’importanza delle feature nel processo decisionale. Questa valutazione si basa sulla riduzione media dell’impurità o su altre metriche aggregate sugli alberi della foresta.
Support Vector Machine (SVM)
Le Support Vector Machine (SVM) sono un potente metodo di apprendimento supervisionato utilizzato principalmente per problemi di classificazione, anche se può essere adattato per la regressione. Le SVM cercano di trovare l’iperpiano che separa meglio le diverse classi nel dataset, massimizzando il margine tra le classi stesse.
1. Come Funzionano:
Le SVM funzionano trovando l’iperpiano ottimale che divide i punti dati di diverse classi nel modo più netto possibile. Un iperpiano è una generalizzazione di un piano a dimensioni superiori, e il margine è la distanza tra l’iperpiano e i punti dati più vicini di ogni classe, chiamati vettori di supporto.
2. Kernel Trick:
Un aspetto chiave delle SVM è l’uso del “kernel trick”, che permette di trasformare i dati in uno spazio a dimensioni superiori dove un iperpiano lineare può separare le classi in modo più efficace. Esistono diversi tipi di kernel, come il kernel lineare, polinomiale, e Gaussiano (RBF - Radial Basis Function), ciascuno con specifiche caratteristiche per adattarsi meglio a diversi tipi di dati.
3. Vantaggi:
- Efficace in spazi ad alta dimensione: Le SVM sono particolarmente efficaci quando il numero di dimensioni è maggiore del numero di campioni.
- Robustezza: Mantengono una buona performance anche quando la separazione tra le classi non è chiaramente definita.
- Versatilità: Grazie al kernel trick, possono adattarsi a problemi complessi non linearmente separabili.
4. Svantaggi:
- Scalabilità: Le SVM possono essere dal punto di vista computazionale intensive e meno efficienti su dataset molto grandi.
- Difficoltà nella scelta del kernel: La performance delle SVM dipende molto dalla scelta del kernel e dei suoi parametri, richiedendo spesso un processo di tuning accurato.
5. Applicazioni:
Le SVM sono utilizzate in una varietà di campi. Nella bioinformatica, per esempio, sono impiegate per la classificazione di sequenze proteiche e la predizione di strutture molecolari. Nel riconoscimento delle immagini, le SVM sono usate per distinguere tra diversi oggetti e volti. Inoltre, trovano applicazione nella classificazione di testi e sentiment analysis, dove possono distinguere tra documenti di diverse categorie o rilevare opinioni positive e negative.
 Localizza
Localizza 




 Stampa
Stampa
 WhatsApp
WhatsApp



